
I encountered the ‘access restriction’ problem when I tried to host a local webpage on to my department’s server.
The problem was that all my images inside the .html file had broken link. (where the annoying broken image icon: ![]() shown everywhere across your website) I double checked my image directory in the .html file and there was nothing wrong with it.
shown everywhere across your website) I double checked my image directory in the .html file and there was nothing wrong with it.
Later I figured out it was the permission of my folder and files problem. It turned out that you CANNOT (at least I’m not sure how) modify the permissions or inspect what the permission of non-users are by right clicking the file/folder and checking ‘Get Info‘ on Mac. You need to use the terminal for that. And it’s all about the Chmod tricks.
Chmod stands for ‘change mode’. It modifies the access permissions to file system objects. The basic syntax is:
chmod [options] file
where ‘options’ is a 10-bit binary 9876543210; if denote the rightmost digit as index 0, then 0, 1, 2 bits control permission of other users, 3, 4, 5 bits control permission of the group, and 6, 7, 8 bits control permission of the user. 10th bit is optional. Each of the three bits represent ‘r’ for read, ‘w’ for write and ‘x’ for execute. An illustration is shown below:
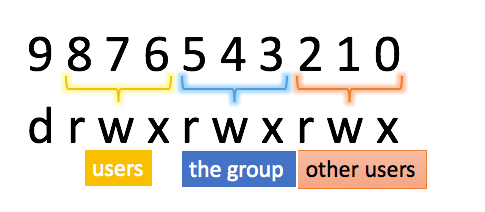
Basically, if you want to allow for ‘r’ for user, then you go to the three bits that control user permission (6, 7, 8 bits) and set 8th bit to one since it controls ‘r’.
Assume we want to change permission of a file to 1) user being able to read, write and execute, 2) group and other users being able to read only. Then we set 2, 5 to one (‘r’ for other users and the group) and 8, 7, 6 to all ones (for user to read, write and execute). Then the 10 bit binary is: 0111100100, which is equivalent as writing in 744 (111–7, 100–4, 100–4).
Instead of using numbers to denote the permission mode, we can also use ‘r’, ‘w’, ‘x’, etc. directly. ‘u’ for user, ‘g’ for group and ‘o’ for others. For example, ‘u+x’ means user is able to execute, ‘o+r’ means others can read.
chmod u+rwx filename
is the same as
chmod 700 filename
If you then want to inspect on what files have what permission, go to your file directory and type:
ls -l filename
Then you are able to figure our why certain images/files are not able to open, and what permissions you have over those files.


